Data Manipulation, Loading and Scraping at the DHOx Digital Health Hack
14 May 2016
Reading time ~5 minutes
Last weekend I helped a couple of teams during the Digital Health Oxford hack weekend (which I was running, and so couldn’t commit to a single project/team). The contribution to each team involved doing a some data mainpulation, extracting, loading etc, and one required using scraping using Selenium, which I’d dabbled with before but never used for anything specific before. Whilst a writeup of the weekend and projects will be on the DHOx website, I wanted to write up a short description of the work I contributed to here.
TBTracker
This project was proposed by the team behind Project Tide, which was started at a DHOx Hack Weekend as an app to improve availability and accuracy of low-cost diagnostics, focusing initially on the LAM test, a specific TB test for people living with HIV.
The main aim of this project, pitched by @cyancollier was to identify what data sources related to TB were available, and to extract, combine and analyse these data to provide create a useful TB data tool / platform. During the end of hack presentations, one of the other participants highlighted Gapminder, which is a fantastic resource. Our aim is not to replicate Gapminder, but to identfy and collate relevant data, hopefully create an API, and additionally build tools to answer specific questions which are currently not supported by Gapminder. The project will also look at how the data that can potentially be collected by ProjectTide can be used to supplement or increase the value of these data, especially in granularity of both location and time. The ProjectTide app is initially being rolled out in Southern Africa, in a partnership with the London School of Hygeine and Tropical Medicine.
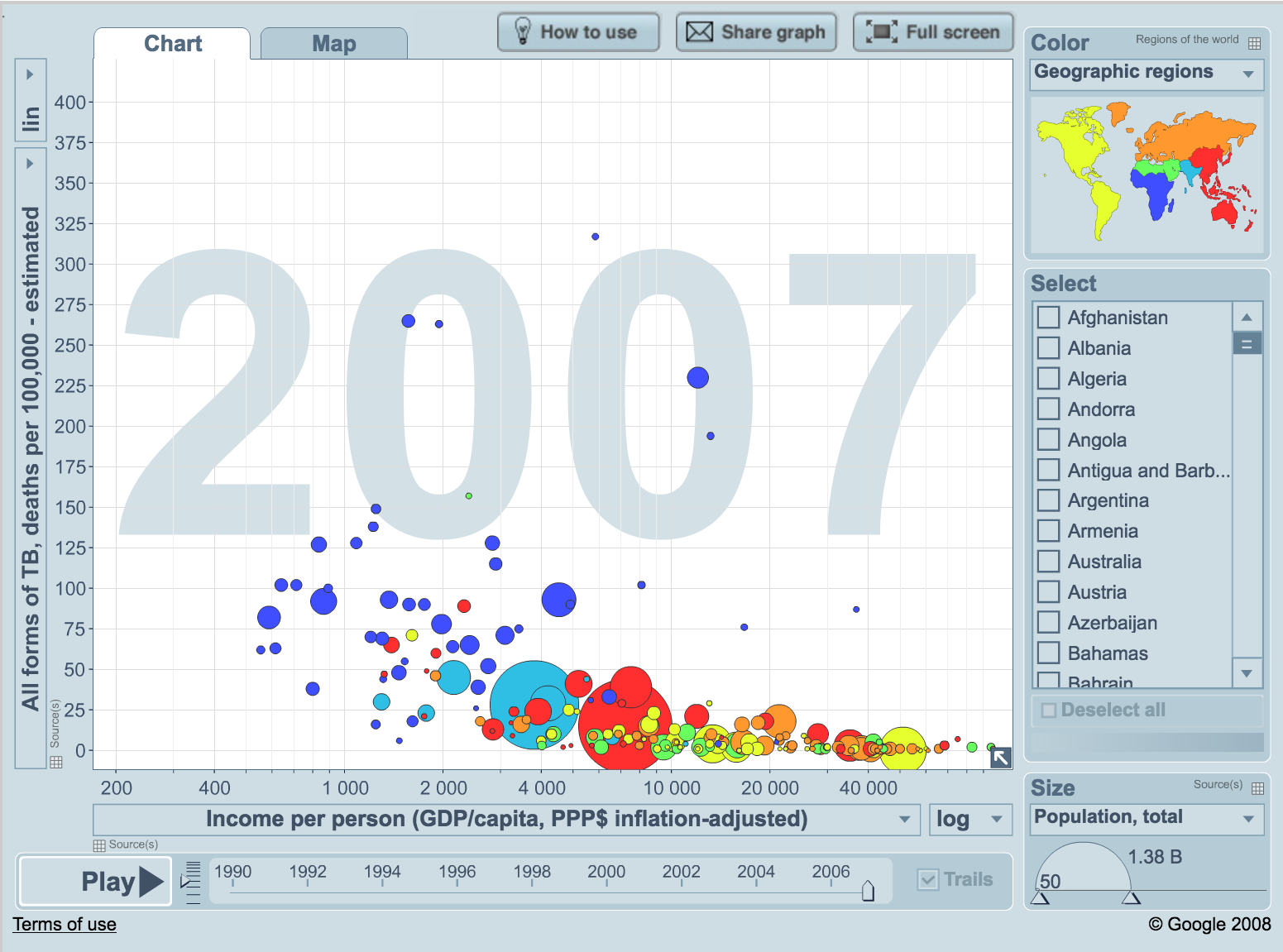
In my limited time during the weekend, I worked on a subset of this project and wrote some code to extract and parse some available data (which we downloaded) from both the World Health Organisation (WHO) and World Bank. This was then imported into a MySQL database, which had been built with appropriate tables/fields. The WHO data is a particularly rich dataset and only a subset of data was exported and loaded to MySQL. The next steps are to perform some initial analysis and then create a prototype API for easy access to this data. This was a relatively easy task, using MySQL, Python, and the xlrd and MySQL-Python libraries.
Most of my projects are in-house, but this needed to provide an easy way for others users to deploy this code, specifically with communicating with the database. A simple way of providing this was to create a config (YAML) file with database credentials and then extracting these as global variables.
# config.yaml
hostname: hostname_eg_localhost
username: username
password: user_password
database: database_name_eg_tbtracker
import MySQLdb as mdb
import yaml
# Initialise mysql connection from config file
with open('config.yaml', 'r') as f:
config = yaml.load(f)
# Define connection
con = mdb.connect(config['hostname'],
config['username'],
config['password'],
config['database']
)
The file commited to the repo is an example, and users need to copy this to create and edit their own config.yaml.
The code and further description for this can be found on the Digital Health Oxford Hackathon GitHub page - under the TBTracker project.
Whatsupp
Whatsupp was an idea pitched to bring together publicly available datasources on the safety and content of nutritional supplements, both in order to highlight supplements that contained substances listed on the WADA banned list, and also to help awareness of unexpected, or potentially harmful substances within those supplements for ordinary consumers (non-competitive athletes). The task I offered to take on was to look at the data available on the High Risk list on the US Anti-Doping Agency website - http://www.supplement411.org/hrl/.
The supplements411.org/hrl site has a list of over 200 High Risk products that are available to buy, but have been tested to contain banned / dangerous / unexpected substances. As part of the terms and conditions, users may not reprint or distribute the High Risk list and only the list on the US Anti-Doping Agency page should be considered up to date, and as such this work was done as a proof of concept.
Supplements411 has a registration page which requires users to fill in some basic credentials and tick a box to confirm the user has read the terms and conditions, before the list is displayed. Saving the page after the list is displayed does not work as a way to save the data (for extracting using lxml/BeautifulSoup etc). The data in the list is also not selectable from the webpage, which may otherwise have allowed for a simple copy/paste and then text processing.
These limitations were a good reason to revisit using Selenium with Python. Although I’ve played around with Selenium before, this was the first time I’ve had reason to use it in a project. There were a couple of tricky bits, including figuring out how to use the non-standard dropdown list, and an exerpt of the code used is posted below. A config file is again used to define MySQL credentials, and also to define user input for registering on the website. The get_css_selector_from_role() function converts a specific role (options for the dropdown list) into a specific css selector.
"""Get data from Supplements411 page
Use Selenium webdriver to go through process to load full page then get/return contents
"""
def get_supp411_page():
browser = webdriver.Firefox()
browser.get('http://www.supplement411.org/hrl/')
firstname = browser.find_element_by_id("textfield-1010-inputEl")
firstname.send_keys(config['supp411_firstname'])
surname = browser.find_element_by_id("textfield-1011-inputEl")
surname.send_keys(config['supp411_lastname'])
email = browser.find_element_by_id("textfield-1012-inputEl")
email.send_keys(config['supp411_email'])
"""
Selecting the role from the 'dropdown' is a bit tricky
- it's not a 'select' element, which would use 'Select' class / methods
- instead it's a unordered list generated by clicking on the combobox (by JS?)
"""
# Click on combobox to display list of divs items
browser.find_element_by_id("combobox-1013-inputEl").click()
# Select specific element 'Other' - use css selector
css_selector = get_css_selector_from_role(config['supp411_role'])
browser.find_element_by_css_selector(css_selector).click()
# Click on checkbox
browser.find_element_by_id("checkbox-1015-inputEl").click()
# Click submit button
browser.find_element_by_id("button-1016").click()
"""After registration details have been supplied and entered
Page reloads with credentials -> get new page contents into variable"""
page_contents = browser.page_source
# Finished getting page contents so can quit browser
browser.quit()
return page_contents
def get_css_selector_from_role(role):
selectors = {
'Athlete': '#boundlist-1029-listEl > ul > li:nth-child(1)',
'Coach': '#boundlist-1029-listEl > ul > li:nth-child(2)',
'Agent': '#boundlist-1029-listEl > ul > li:nth-child(3)',
'Medical professional': '#boundlist-1029-listEl > ul > li:nth-child(4)',
'Parent': '#boundlist-1029-listEl > ul > li:nth-child(5)',
'Sport administrator': '#boundlist-1029-listEl > ul > li:nth-child(6)',
'Other': '#boundlist-1029-listEl > ul > li:nth-child(7)',
}
return selectors[role]
The code and further description for this can be found on the Digital Health Oxford Hackathon GitHub page - under the Whatsupp project.